3.2 F-toets
In jaar 1 zijn jullie de t-toets tegengekomen. Hiermee test je (in het geval van een onafhankelijke t-toets) of de gemiddelden van twee groepen significant van elkaar verschillen. Met andere woorden:
- Hoe waarschijnlijk is het dat je een minstens zo groot verschil krijgt in de steekproefgemiddelden, terwijl er in werkelijkheid geen verschil is (dus de kansverdeling onder de H0).
- Is die waarschijnlijkheid (de p-waarde) minder dan de drempelwaarde (\(\alpha\), meestal 0,05), dan wordt de H0 verworpen en zeggen we dat het verschil significant is.
Wat je (of de computer) doet is een kansverdeling maken van de mogelijke verschillen in gemiddelden.
Begin twintigste eeuw heeft Ronald Fisher (zie wikipedia) een alternatieve manier ontwikkeld op basis van verklaarde variantie: de F-toets:
\[F=\frac{MS_{verklaard}}{MS_{rest}}\] MS staat voor de Mean Squares, oftewel de gemiddelde kwadraatafstand. Deze manier van toetsen wordt variantieanalyse genoemd, of op zijn Engels Analysis of Variance: ANOVA.
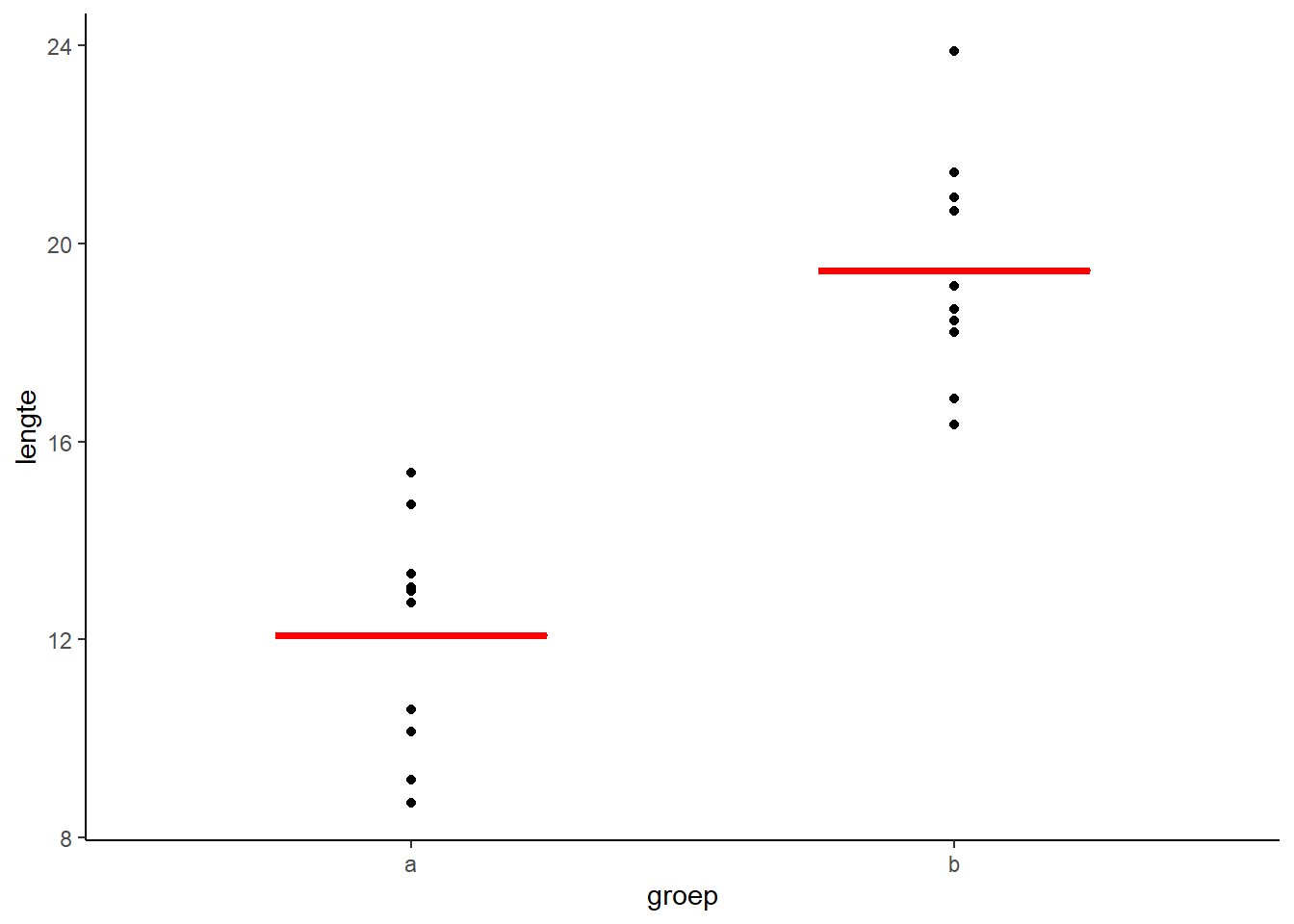
Als voorbeeld de data uit de vorige oefening. De totale variantie in de data vind je door een horizontale lijn (dus a=0) door het gemiddelde te trekken (dus b zo kiezen dat SSE minimaal is). De gemiddelde kwadraatafstand wordt dan de gevonden SSE gedeeld door 29 (het aantal waarnemingen - 1). Dat is MStotaal.
Als je nu a en b zo kiest dat de SSE geminimaliseerd wordt, hou je restvariantie over. Deel dit door 29 en je hebt MSrest. De verklaarde variantie is MStotaal - MSrest.
Gelukkig hoef je niet zelf te goochelen met deze varianties, daar hebben we R voor. Wat je wel moet onthouden is dat hoe beter de fit van het statistisch model, des te hoger F wordt.
Met wat extra gegoochel met statistisch formules kan je aantonen dat de kansverdeling van F dezelfde is als de kansverdeling van t2. De berekende waarde voor F (via bovenstaande formule) geeft precies dezelfde uitkomst als de berekende waarde voor t. Kijk maar eens naar onderstaande figuur en de bijbehorende toetsen.
t.test(df$lengte~df$groep, var.equal=TRUE)##
## Two Sample t-test
##
## data: df$lengte by df$groep
## t = -7.1998, df = 18, p-value = 1.063e-06
## alternative hypothesis: true difference in means between group a and group b is not equal to 0
## 95 percent confidence interval:
## -9.529953 -5.224566
## sample estimates:
## mean in group a mean in group b
## 12.07949 19.45674anova(lm(df$lengte~df$groep))## Analysis of Variance Table
##
## Response: df$lengte
## Df Sum Sq Mean Sq F value Pr(>F)
## df$groep 1 272.12 272.120 51.838 1.063e-06 ***
## Residuals 18 94.49 5.249
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Vergelijk je de p-waardes, dan zie je dat ze precies gelijk zijn. En de F-waarde is het kwadraat van de t-waarde (ga zelf na).
Waarom heb je dan toch de t-toets moeten leren? Twee redenen:
- Met een t-toets kan je ook eenzijdig testen (H1: a<b)
- Bij een t-toets heb je de keuze om wel of niet de aanname te maken dat de variantie gelijk is voor beide groepen. Bij ANOVA maak je altijd die aanname!